Discord Bots using Microservices
Your extensive introduction to microservices-based bots on discord.



Table of contents
Introduction
Building administrations utilizing a microservices engineering offers various advantages, particularly when joined with the serverless choices cloud suppliers can offer. This blend permits you to construct an assortment of little administrations, that cost very little, however can increase with insignificant to no extra exertion and handle burst scaling all around well. It's difficult to progressively scale your bot across numerous cycles or even servers relying upon current burden. Therefore with microservices, you can call techniques for the Discord Gateway or the Discord REST API from anyplace without dreading a ratelimit crash. With current implementations of discord libraries, every shard has it's own reserve, you will definitely have duplicate data in your store, which is a misuse of memory that your bot could utilize.
Although, as always there is a limitation to this. The first and foremost is the learning curve. For beginners sticking with pre-built frameworks is the best option. You'll require a method for moving ws events from one layer to another, this transport layer must be disappointment evidence and ought to be all around as exceptionally accessible as could be expected, since your bot will be inert when it falls flat.
Key points
- Cache Reduction
Assuming your bot is in ~2,000 guilds (discord's requirement), you will require sharding. As I've previously stated when you shard your bot, each shard creates it's own cache i.e., decentralized cache. Therefore, there is a big chance of duplication. When you have centralized cache(microservice paradigm) the duplication issue is resolved.
- Scaling
This might be the single most important point as to why microservice bots should be adopted. As your bot grows, scaling becomes an issue, especially when you're using a API Library to aid your development process. Here's the problem with the Discord API:
Discord counts each successful IDENTIFY as one connection.
Discord has a limit of 1000 to 2000 connections a day, for each shard depending upon the amount of guilds your bot is in. Once you hit the limit, your token resets. This is incredibly hard to adapt to, with discord API Libraries.
Clients are limited to 1000 IDENTIFY calls to the websocket in a 24-hour period. This limit is global and across all shards, but does not include RESUME calls. Upon hitting this limit, all active sessions for the bot will be terminated, the bot's token will be reset, and the owner will receive an email notification. It's up to the owner to update their application with the new token. - Discord Documentation
- Freedom
You have the freedom to utilize and use any tech-stack you'd like. Rather being centralized to one. How's that you ask?
- Let's assume you want to use discord.js, a NodeJS Discord API Wrapper. Points to be noted are:
- You need to use the in-built (in-memory) cache, and can neither extend nor manipulate it.
- You are centralized into using one single programming language (Javascript or Typescript).
- Inefficient memory utilization, especially if you wanted to use a external database for cache.
- Let's assume you're using A Microservice Paradigm. Points to be noted are:
- You are not restricted one certain language. For example: You could create a centralized database s service in rust, a cache service in golang, the bot in Kotlin, a rest API for any api services/dashboard services in Js/Ts.
- Your cache can easily be connected to a centralized external database.
- Less memory utilization since your cache isn't in-memory anymore.
- No Ratelimit Fear
There are no limitations on the quantity of restarts your Bot might do once every 24 hours since the actual Bot isn't straightforwardly associated with the Discord Gateway however rather gets its occasions from an intermediary(here, the proxy). You can call strategies for the Discord Gateway or the Discord REST API from anyplace without dreading a ratelimit crash.
Structural Concept
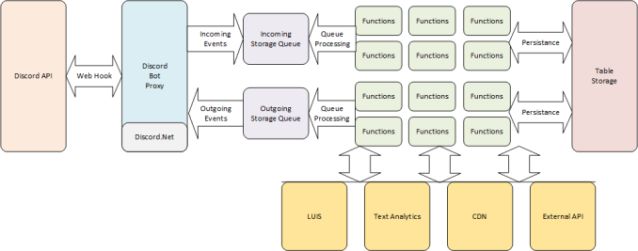
Both of these conceptual structures, oversee two main processes:
- Gateway
- Rest
The gateway is utilized as a cause of events, which were set off by clients on Discord, yet in addition as a method for executing a little arrangement of activities. Aside from this, the gateway additionally fills a subsequent need in furnishing you with beginning data when you initially associate with it, this underlying information contains data like the guilds of the bot and their properties. Clients associate with the gateway by means of WebSocket with json or etf (Erlang term design) encoding. Furthermore the gateway can pack bundles shipped off the client, this is done by means of zlib or zlib-stream. While making another association with the gateway, the client should IDENTIFY itself. This IDENTIFY call makes another meeting, to give an approach to guaranteeing some degree of solidness clients can RESUME a meeting when the hidden association was detached in some way Everything else just revolve around the two main interactions.
The REST API is utilized as an approach to executing activities like communicating something specific, refreshing properties of a channel, and so on Normally the REST API is brought in light of a formerly gotten occasion from the passage, similar to a message from a client containing an order for the bot.
All of these processes are independent of each other rather being knit together. For communication between each process/system a message broker is used. Publish, Call & Consume are the three methods with which a message broker works. At the point when an oevent is produced and a response isn't needed, the client which made the event will "publish" it to different clients. Each "publish" event should return A Event Name, for the receiver to comprehend what the event was & what it should do next, and the unique ID of this event emission. "Call" acts in basically the same manner to "publish, with the exception of the calling client will sit tight for a solitary response from another client. At the point when a client consumes, it flags an expectation(intent) to get events for its gathering. The client should indicate which events it expects to get.
Each message that the broker sends, the receiver must/can do 2 things:
- Acknowledge
- Reply
Acknowledging a message merely means that the receiver has received the message. At the point when a message is recognized, it is eliminated from forthcoming state and will never again be re-conveyed to different buyers/consumers/receivers assuming that the beneficiary client kicks the bucket or times out.
Replying to a message merely means that the receiver was asked for a certain set of information and must yield the sender with adequate data. At the point when a client gets a "publish" event, it can decide to answer; in the event that the source client is tuning in, it will get the response.
Caching in this whole set of concepts is the most straightforward concept. Caching can build execution, versatility, and accessibility for microservices. The principle thought is decreasing inactivity with store and makes application quicker. Whenever the quantity of solicitations are expanded, reserving will be truly significant for obliging entire solicitations with high accessibility. Caching likewise give to keep away from re-estimation processes. In the event that one activities compute by one server, other application can consume determined information from reserve. In Microservices designs are ordinarily carry out a dispersed storing engineering. The main reason for caching is to reduce/limit the amount of Discord API calls, so that we do not get ratelmited.
Libraries
Here are some of the libraries that provide you a headstart with microservice implementations:
Hope you liked this blog! Until next time 🦄